# 2024YLCTF WP MISC 篇
原创:源鲁安全实验室
搬的官方 wp,因为好多题忘了咋解的了...
# Round 1
# 乌⻳⼦啦
拿到⼀串 base64 的编码,观察发现这是⼀个图⽚转 base64 的操作,cyberchef 转成图⽚
然后可以得到⼀张全都是 01 的图⽚,我们⽤ ocr 将它识别出来。
因为只有 01 所以 ocr 的准确率⽐较⾼,由于图⽚较⻓可考虑分 10 段 ocr 识别。
由于只有 01 考虑⿊⽩像素,可能是⼆维码,写个脚本转换即可(也可随波逐流 10 字符
串转图⽚)
from PIL import Image
from zlib import *
import math
str = ""
MAX = int(math.sqrt(len(str)))
print(MAX)
pic = Image.new("RGB",(MAX,MAX))
i=0
for y in range(0,MAX):
for x in range(0,MAX):
if(str[i] == '1'):
pic.putpixel([x,y],(0,0,0))
else:pic.putpixel([x,y],(255,255,255))
i = i+1
pic.show()
pic.save("flag.png")
得到⼆维码后 扫码即可得到 flag: YLCTF{f6a6f8cf-c25b-49a8-8f17-c8fbd751faa4}
# hide_png
打开图⽚可以看到,图⽚隐隐约约有⼀个内嵌的图⽚

但是看不出具体是什么,放⼤查看像素的关系,可以发现这样⼀个式⼦【从左上⻆第⼀个点算作 (0,0),其位置为 (15,64),最终可得到对应位置的式⼦ (i+5)*3,(j+4)*16】
需要再统计⼀下,内嵌的这个图⽚的⻓宽像素各有多少【最右下⻆为 (1968,1312) 对应 i j 为 651,78 所以共 652x79 个】,然后编写脚本来读取各个点的像素。
from PIL import Image
f = Image.open('./attachments.png')
img = Image.new("RGB", (652,79))
for i in range(650):
for j in range(79):
t = f.getpixel(((i+5)*3,(j+4)*16))
img.putpixel((i,j),(t))
img.show()
img.save('output.png')
# plain_crack
本题使⽤ pyminizip 对⽂件进⾏了加密压缩
那么明⽂爆破需要⼀个压缩类型⼀样且压缩后 crc32 ⼀样的 zip 才可以进⾏爆破
# -*- coding:utf8 -*-
import pyminizip
from hashlib import md5
import os
def create(files, zfile):
pyminizip.compress_multiple(files,[], zfile, None, 0)
pass
if __name__ == '__main__':
files = ['build.py']
zfile = 'build.zip'
create(files, zfile)
所以⽤上⾯这个脚本压缩 build.py,然后再⽤ ARCHRP 进⾏明⽂爆破即可
明⽂爆破可能会出现跑很久,然后说没找到⼝令,但实际上停⽌后就可以直接另存为
解密后的压缩包了。
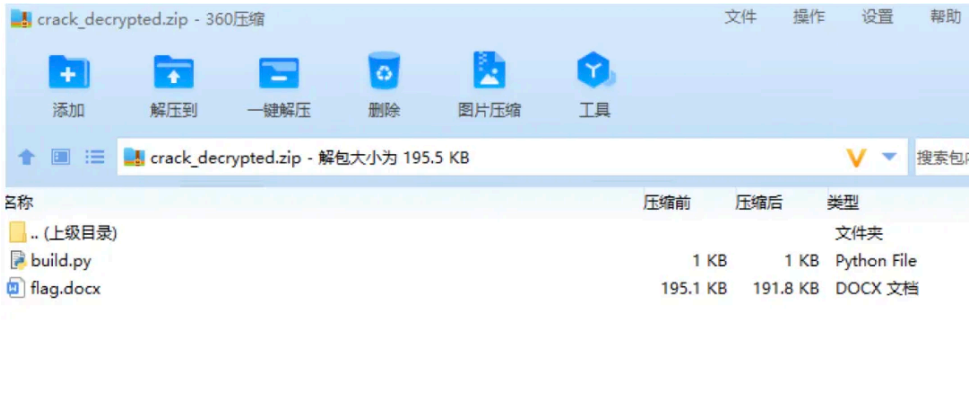
然后下⼀个知识点是 word ⽂件实际上可以看作是 zip ⽂件,改个后缀,查看⼀下 media
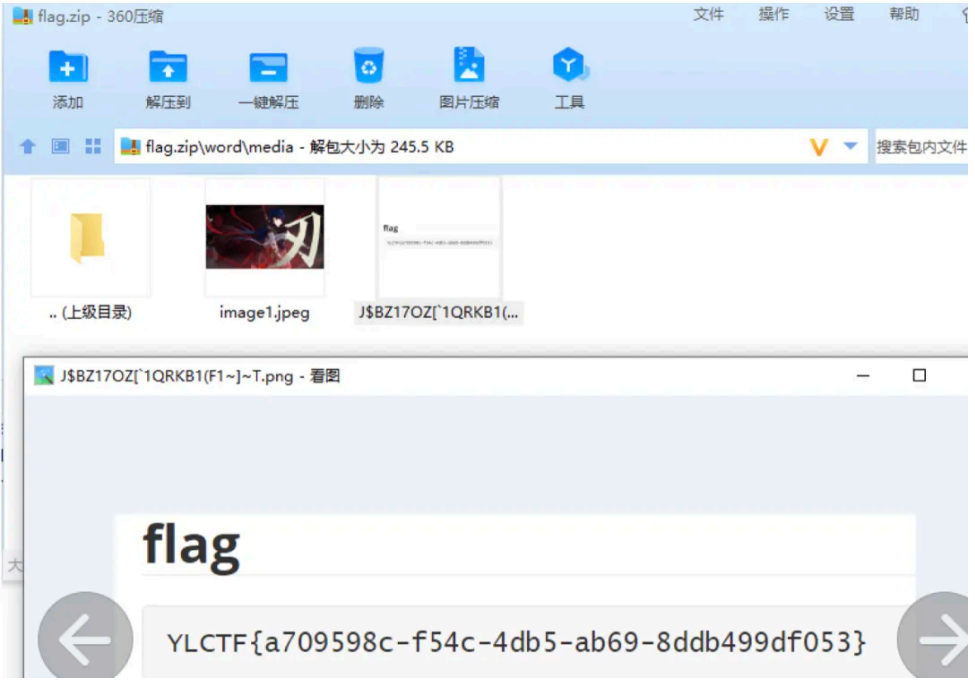
⽂件夹 ⾥⾯就有 flag 的图⽚了。
# pngorzip
这题的主要思路是 lsb 图⽚隐写,需要借助到 stegsolve ⼯具来查看隐写
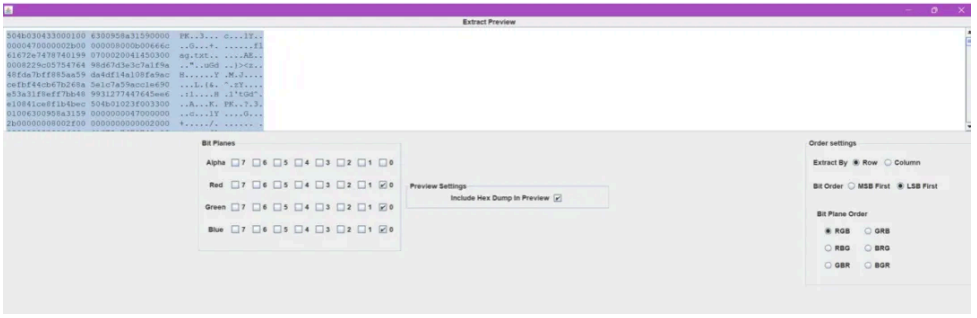
直接查看 RGB 三通道的 lsb,可以发现存在⼀个 PK 头,应该是个压缩包,给他 save bin
出来。但是压缩包有密码,查看到压缩包的描述有⼀个 hint。
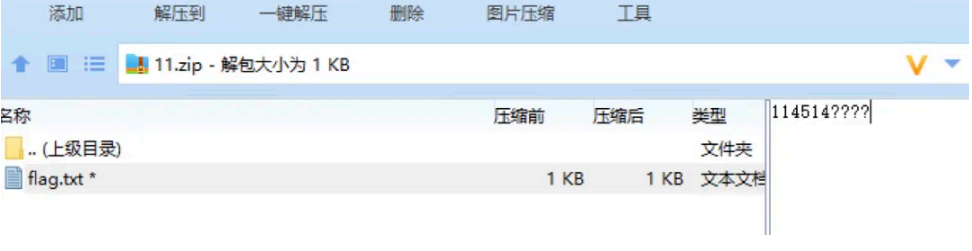
考虑到可能是掩码爆破,使⽤ ARCHPR 的掩码爆破就可以解密出压缩包密码了 114514giao ,查看 txt 得到 flag: YLCTF{d359d6e4-740a-49cf-83eb-5b0308f09c8c}
# whatmusic
拿到⼀个有密码的压缩包,压缩包⾥⾯有⼀个 password 的⽂件。
我们拖进 010 中查看,发现⽂件的最末尾有 PNG% 的倒置,考虑可能是 byte 翻转,写脚
本翻转回来,或者厨子里面也有工具。
def reverse_byte_data(image_path, output_path):
# 读取图⽚的⼆进制数据
with open(image_path, 'rb') as file:
byte_data = file.read()
# 翻转⼆进制数据流
reversed_byte_data = bytearray(reversed(byte_data))
# 将翻转后的⼆进制数据流写⼊新的⽂件
with open(output_path, 'wb') as file:
file.write(reversed_byte_data)
if __name__ == "__main__":
import sys
if len(sys.argv) != 3:
print("Usage: python reverse_byte_data.py <input_image_path> <output_image_path>")
sys.exit(1)
input_image_path = sys.argv[1]
output_image_path = sys.argv[2]
reverse_byte_data(input_image_path, output_image_path)
print(f"Image byte data reversed and saved to {output_image_path}")
byte 翻转回来后,图⽚只有的宽只有 0x15 像素,考虑可能被隐藏了宽,我们到 010 中修改宽度即可。然后图⽚是镜像的,还需要写脚本镜像回来,不然很难看懂。这里方法很多,不过留一个脚本吧。
from PIL import Image
def flip_image(image_path, output_path):
# 打开图⽚
with Image.open(image_path) as img:
# ⽔平翻转图⽚(镜像)
flipped_img = img.transpose(Image.FLIP_LEFT_RIGHT)
# 保存翻转后的图⽚
flipped_img.save(output_path)
if __name__ == "__main__":
import sys
if len(sys.argv) != 3:
print("Usage: python flip_image.py <input_image_path> <output_image_path>")
sys.exit(1)
input_image_path = sys.argv[1]
output_image_path = sys.argv[2]
flip_image(input_image_path, output_image_path)
print(f"Image flipped and saved to {output_image_path}")
这样就得到了压缩包的密码 &*asdsaxc141123123xcoaa#
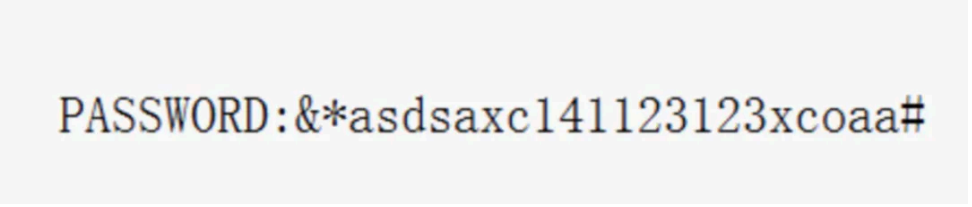
打开压缩包后,还是把 flag 拖进 010 中,根据 hint1 的提示,看到 lyra 字眼,这是 google 的⼀个压缩⾳频的项⽬。
有相关脚本,kali 里面可以解,然后利⽤以下命令进⾏解密即可。
bazel-bin/lyra/cli_example/decoder_main --encoded_path=$HOME/temp/flag.lyra --o utput_dir=$HOME/temp/
得到⼀段⾳频后,发现他念了⼀串东⻄,⽽且语速有点快,考虑可以使⽤语⾳识别等操作。通过 0.25 倍速或 0.5 倍速听可得到 YLCTF 的 flag。
# trafficdet
本题为恶意流量分类识别
因为给的 train 有⼀点点太全了,稍微拟合于 test,所以采⽤了 99% 的 acc 作为判断,如果⽤ f1 的话有点离散了,不太合适。
有很多的算法可以⽤于流量分类,但是由于数据⽐较多,选⽤随机森林算法处理这类问题实际上会⽐深度学习的⽅法好很多,所以可以使⽤ sklearn 的随机森林库进⾏建模,然后⾃⼰⼿动筛出掉⼀些⽆⽤特征即可。
如果发现 acc 可能差的不多,可以调整⼀下决策树数量,虽然⼀般来说越多决策树越好,但是对于 0.001%~0.01% 级别的 acc 来说,使⽤越⼤的决策树可能会导致 acc 降低。包括随机数 seed 和训练的时候的分割⽐例等。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, PolynomialFeatures
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
data = pd.read_csv('train.csv')
for col in data.columns:
if data[col].dtype == 'object' and data[col].name != 'Label':
le = LabelEncoder()
data[col] = le.fit_transform(data[col])
X = data.drop(columns="Label",axis=1)
y = data['Label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, rando
m_state=613)
rf = RandomForestClassifier(n_estimators=1500, random_state=531,n_jobs=-1)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
joblib.dump(rf, 'rf_model.pkl')
import pandas as pd
from sklearn.preprocessing import LabelEncoder, PolynomialFeat
ures
from sklearn.ensemble import RandomForestClassifier
import joblib
rf = joblib.load('rf_model.pkl')
test_data = pd.read_csv('test.csv',encoding="utf-8")
for col in test_data.columns:
if test_data[col].dtype == 'object':
le = LabelEncoder()
test_data[col] = le.fit_transform(test_data[col])
predictions = rf.predict(test_data)
pred = pd.DataFrame(predictions, columns=['Label'])
pred.insert(0, 'id', range(1, len(pred) + 1))
pred.to_csv('predictions.csv', index=False)
# SinCosTan
下载附件后,010 打开发现是个 wav ⽂件,根据题⽬提示的 SinCosTanOrd,猜测需要把⾳频⾥的 ascii 数据给提取出来
例如 png 图像⽂件为 89504b 转换后为 565753485298 ,zip 压缩包⽂件为 504b0304 转换 后为 534852664851
有了思路后编写 Python 脚本
from scipy.io import wavfile
samplerate, data = wavfile.read('flag.wav')
for i in range(len(data)):
if 53 == data[i] and 48 == data[i+1] and 52 == data[i+2] and 66 == data[i+3] and 48 == data[i+4] and 51 == data[i+5]:
print("zip: " + str(i))
if 56 == data[i] and 57 == data[i+1] and 53 == data[i+2] and 48 == data[i+3] and 52 == data[i+4] and 101 == data[[i+5]]:
print("image: " + str(i))
定位数据位置,得到(每个⼈的数据位置都是不⼀样的)
with open("flag_output.zip", "wb") as f:
hex_string = ""
try:
for i in range(zip, zip+478):
hex_value = chr(int(data[i]))
hex_string += hex_value
binary_data = bytes.fromhex(hex_string)
f.write(binary_data)
except ValueError as e:
print(f"{len(hex_string)}")
with open("flag_output.png", "wb") as f:
for i in range(image1, image1+325878):
hex_value = chr(int(data[i]))
print(hex_value, end = "")
with open("flag_watermark_output.png", "wb") as f:
hex_string = ""
try:
for i in range(image2, image2+84562):
hex_value = chr(int(data[i]))
hex_string += hex_value
binary_data = bytes.fromhex(hex_string)
f.write(binary_data)
except ValueError as e:
print(f"{len(hex_string)}")
接着把所有数据给提取出来,得到下⾯⼏个⽂件。

hint 内容为宽零隐写,告知盲⽔印的种⼦为 114514
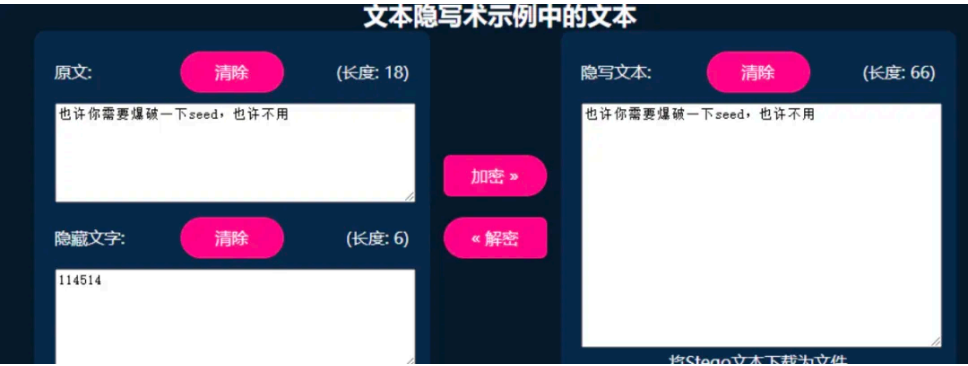
得知 seed 后,去解⼀下盲⽔印即可,羊驼也行。
python3 bwmforpy3.py decode flag_output.png flag_watermark_output.png flag.png --seed 114514

# Round 2
# 滴答滴
使⽤ 010 打开⽂件可以发现全部都是 00 和 FF,⼀般来说这是可以⽤于表示电平信号,但是问题是不知道信号的编码是什么。
由于题⽬描述给了 man~ ,所以可以尝试⼀下曼切斯特编码来表示。
def read_from_file(filename):
# 从⽂件中读取⼆进制数据
with open(filename, 'rb') as file:
return file.read()
def manchester_to_binary(manchester_data):
# 将曼切斯特编码的数据转换回⼆进制字符串
binary_str = ''
i = 0
while i < len(manchester_data):
if manchester_data[i] == 0 and manchester_data[i+1] ==255:
binary_str += '0'
elif manchester_data[i] == 255 and manchester_data[i+1] == 0:
binary_str += '1'
i += 2 # 每次处理两个字节
return binary_str
def binary_to_char(binary_str):
# 将⼆进制字符串转换回ASCII字符
return ''.join([chr(int(binary_str[i:i+8], 2)) for i in range(0, len(binary_str), 8)])
# 示例使⽤
filename = "attachment" # 输⼊⽂件名
manchester_data = read_from_file(filename)
binary_str = manchester_to_binary(manchester_data)
print(binary_str)
ascii_str = binary_to_char(binary_str)
print(f"解码后的ASCII字符串: {ascii_str}")
# 解码后的ASCII字符串: YLCTF{7d160084-4dd5-4eec-bf1f-12f3ad8c8a6b}
# 听~
下载题⽬附件发现为 wav ⽂件,猜测考点为 wav 隐写,通过 audacity 观察波形、频谱并没有发现其它内容。考虑利⽤ DeepSound 进⾏解压,发现⼀个压缩包,结果如下:
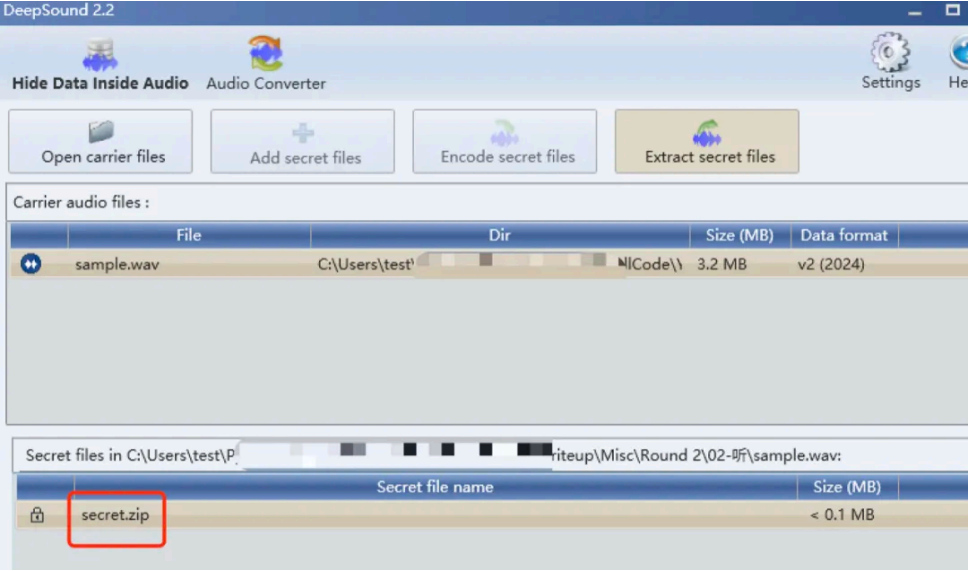
该压缩包存在加密,通过爆破得到压缩包⼝令,如下图:
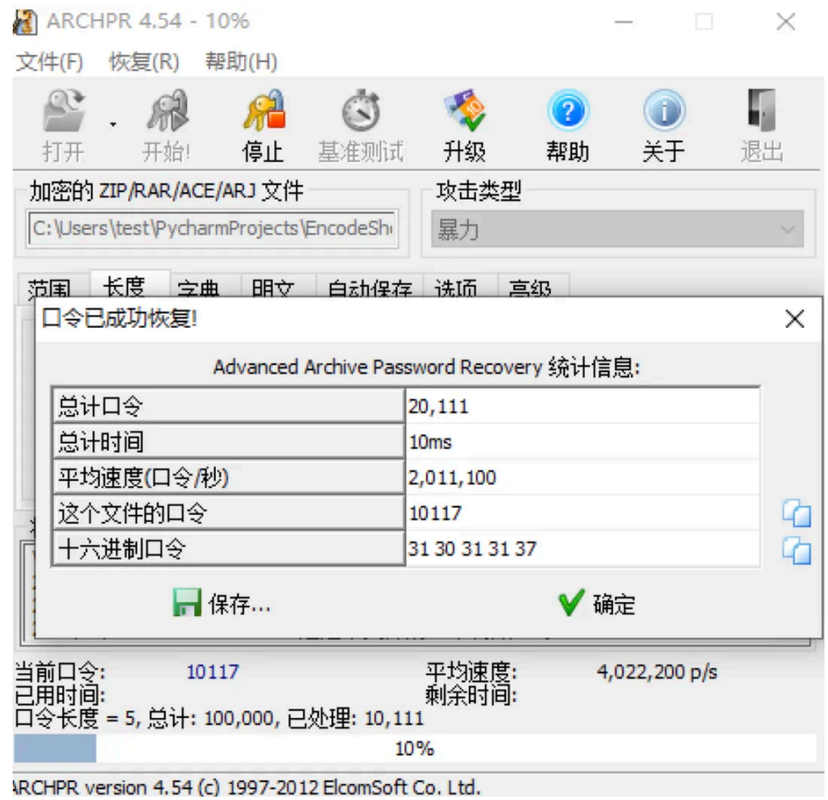
解压发现存在⼀张图⽚,发现为 png 图⽚,利⽤ StegSolve 进⾏分析,发现存在以下信息:
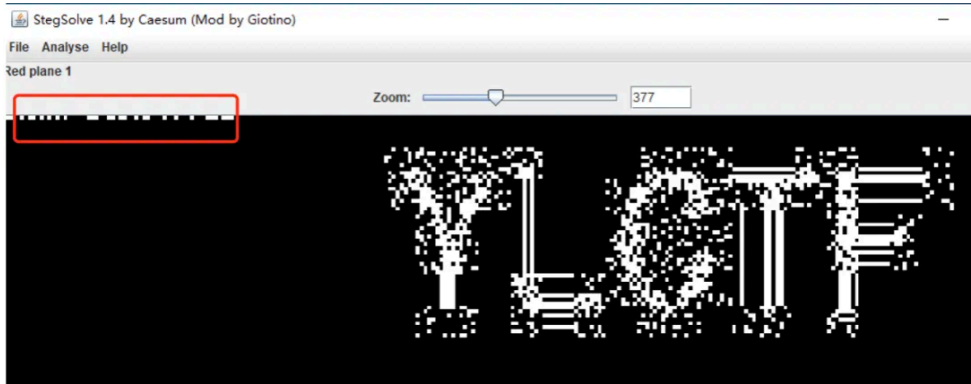
判断为 lsb 隐写,那么利⽤ data extract 功能,选取如下:
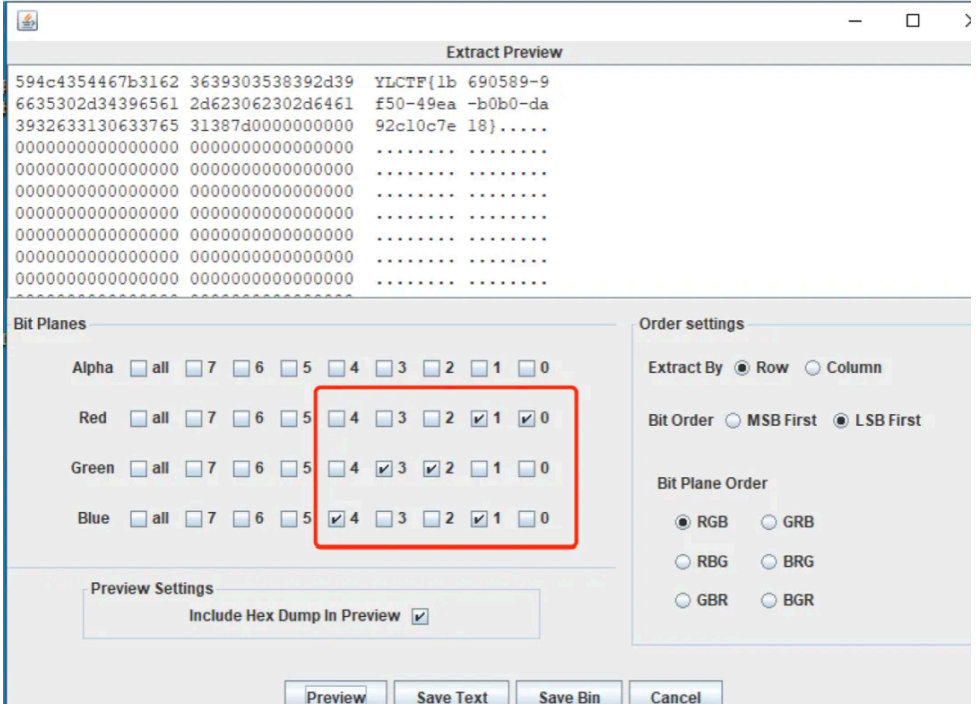
# Trace
通过 010editor 打开附件 发现结尾为 base64 编码的数据,复制后进⾏解码
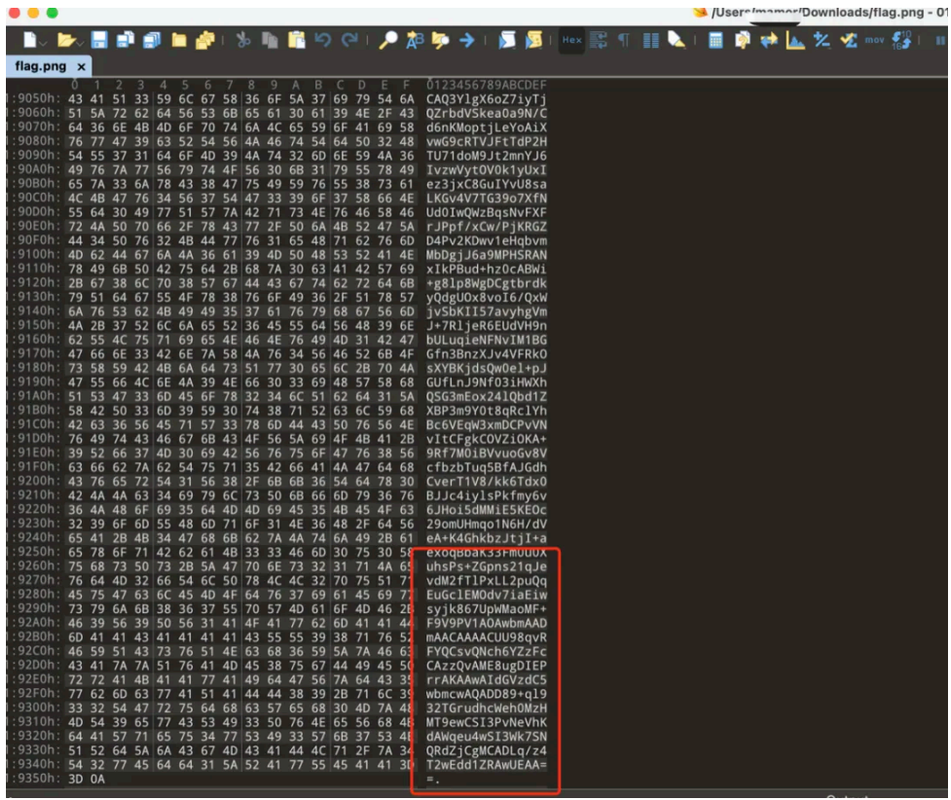
复制解码后发现为 rar 压缩包
通过 rar2john 获取 hash 值后,利⽤ hashcat 进⾏解密,如下图:

根据题⽬提示密码为 6 位爆破得到如下结果:

解压压缩包,得到⼀张图⽚,观察图⽚内容发现该形式类似于猫脸变换,利⽤脚本:
def arnold_encode(image, shuffle_times=10, a=1, b=1, mode='1'):
image = np.array(image)
arnold_image = np.zeros(shape=image.shape, dtype=image.dtype)
h, w = image.shape[0], image.shape[1]
N = h
for _ in range(shuffle_times):
for ori_x in range(h):
for ori_y in range(w):
new_x = (1*ori_x + b*ori_y)% N
new_y = (a*ori_x + (a*b+1)*ori_y) % N
if mode == '1':
arnold_image[new_x, new_y] = image[ori_x, ori_y]
else:
arnold_image[new_x, new_y, :] = image[ori_x, ori_y, :]
return Image.fromarray(arnold_image)
import numpy as np
from PIL import Image
def arnold_decode(image, shuffle_times=10, a=1, b=1, mode='1'):
image = np.array(image)
decode_image = np.zeros(shape=image.shape, dtype=image.dtype)
h, w = image.shape[0], image.shape[1]
N = h
for _ in range(shuffle_times):
for ori_x in range(h):
for ori_y in range(w):
new_x = ((a*b+1)*ori_x + (-b)* ori_y)% N
new_y = ((-a)*ori_x + ori_y) % N
if mode == '1':
decode_image[new_x, new_y] = image[ori_x, ori_y]
else:
decode_image[new_x, new_y, :] = image[ori_x, ori_y, :]
return Image.fromarray(decode_image)
img = Image.open('flag.png')
decode_img = arnold_decode(img)
decode_img.save('flag-output.png')
# IMGAI
本题是 MISNT ⼿写图像数据集,题⽬的问题在于标签⽜头不对⻢嘴。
mapping = {1: 7, 2: 3, 4: 5, 6: 9, 8: 0,7:1,3:2,5:4,9:6,0:8}
按照这个替换表来实现数据替换。
远程服务端实现了⼀个图⽚输出的功能,将 36 张 640x480 的图⽚输出成 2 进制。
所以需要通过 pwntools 的 recv 来读取⼆进制信息,再通过 PIL 将⼆进制信息转换成图⽚,再将图⽚进⾏预测,最后使⽤ pwntools 的 sendline 与终端进⾏交互。
给出了⼀个 CNN 定义,需要将这个定义写⼊ test 脚本中,后⾯直接利⽤ model.pth 进⾏预测就⾏了。
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
import numpy as np
from pwn import *
# 定义与训练时相同的CNN模型
class MNISTCNN(nn.Module):
def __init__(self):
super(MNISTCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5)
self.fc1 = nn.Linear(64 * 5 * 5, 1024)
self.fc2 = nn.Linear(1024, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 64 * 5 * 5) # 展平
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# 加载模型权重
model = MNISTCNN()
model.load_state_dict(torch.load('model.pth'))
model.eval()
# 定义变换
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# 预测图像
def predict_image(image_path, model, transform):
image = Image.open(image_path).convert('L') # 转换为灰度图像
image = transform(image).unsqueeze(0) # 增加批处理维度
with torch.no_grad():
outputs = model(image)_, predicted = torch.max(outputs, 1)
return predicted.item()
def binary_to_image(binary_str, width, height):
if len(binary_str) != width * height:
raise ValueError("字符串⻓度与图像尺⼨不匹配")
img = Image.new('1', (width, height))
binary_array = np.array(list(binary_str), dtype=np.uint8)
binary_array = binary_array.reshape((height, width))
pixels = img.load()
for i in range(height):
for j in range(width):
pixels[j, i] = 255 if binary_array[i, j] == 1 else 0
return img
io = remote("challenge.yuanloo.com",28396)
io.recvuntil("Welcome to YLCTF,please guess number\n")
for i in range(1,37):
mess = io.recvuntil(f"i")
mess = str(mess)[2:-4]
recovered_img = binary_to_image(mess, 640, 480)
recovered_img.save("1.png")
predicted_label = predict_image("1.png", model, transform)
key = ""
key += str(predicted_label)
print(i)
io.recvuntil("\n")
io.sendline(str(predicted_label))
print(key)
io.interactive()
# LiteOS
开局⼀个 wav,DeepSound 隐写
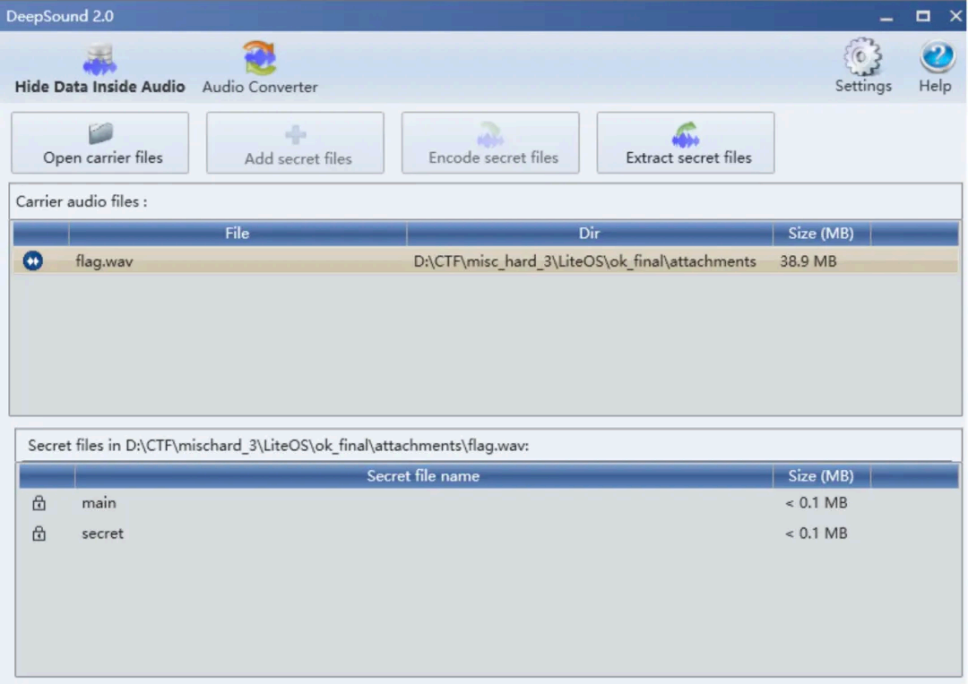
将所有数据⽂件提取出来
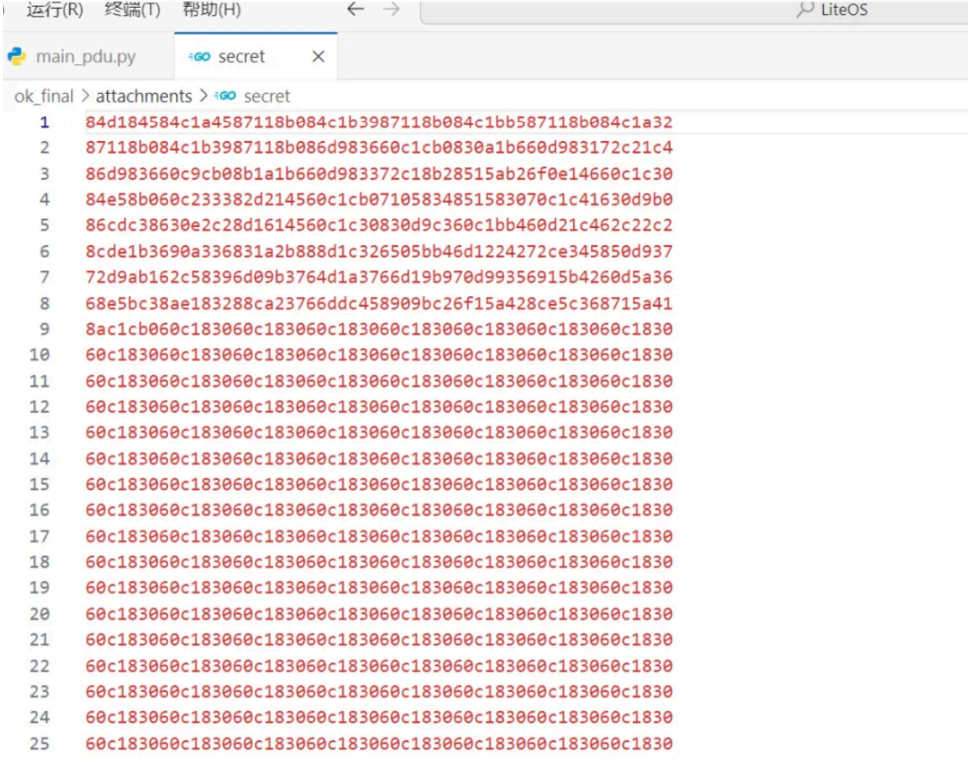
secret 为⼀个 pdu ⽂件,需要编写 7 ⽐特位解码程序
codes = '''84d184584c1a4587118b084c1b3987118b084c1bb587118b084
c1a3260
87118b084c1b3987118b086d983660c1cb0830a1b660d983172c21c460
86d983660c9cb08b1a1b660d983372c18b28515ab26f0e14660c1c3060
84e58b060c233382d214560c1cb07105834851583070c1c41630d9b060
86cdc38630e2c28d1614560c1c30830d9c360c1bb460d21c462c22c260
8cde1b3690a336831a2b888d1c326505bb46d1224272ce345850d93760
72d9ab162c58396d09b3764d1a3766d19b970d99356915b4260d5a3660
68e5bc38ae183288ca23766ddc458909bc26f15a428ce5c368715a4160
8ac1cb060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c183060c183060
60c183060c183060c183060c183060c183060c183060c18306ad60c160'''
def from_hex(s):
b_str = ''.join(format(int(s[i:i+2], 16), '08b') for i in
range(0, len(s), 2))
return b_str.rstrip('0')
def from_bit(s):
d_str = ''.join(chr(int(s[i:i+7], 2)) for i in range(0, le
n(s), 7))
return d_str
for code in codes.split('\n'):
code_bit = from_hex(code)
code_text = from_bit(code_bit)
print(code_text)
脚本解密完后得到的是⼀个⼆进制⽂件,另存为 os.bin
qemu 搭配 gdb 起个远程调试
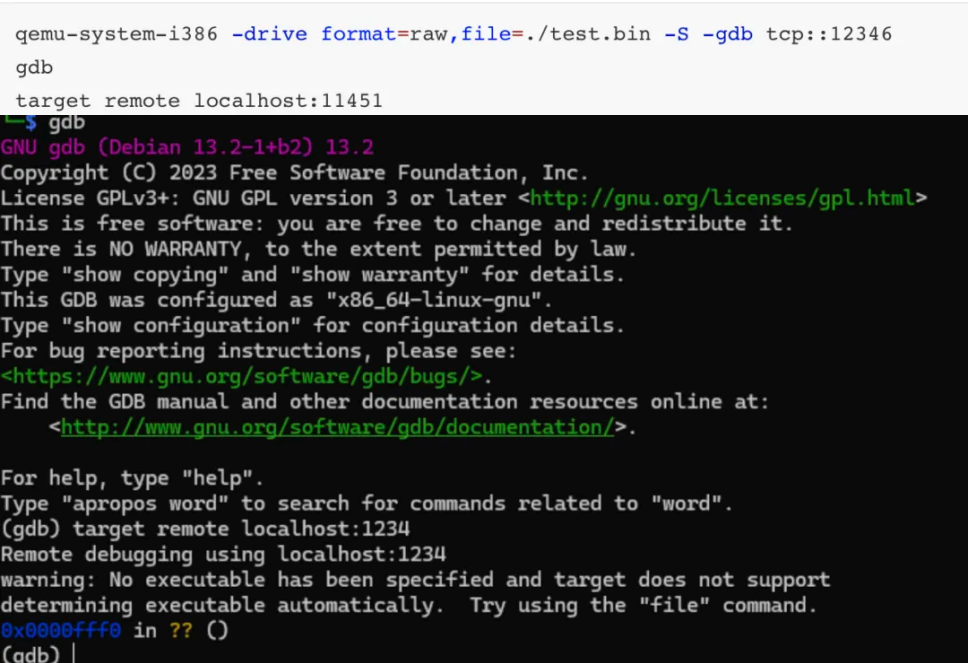
下断点到 0x7c00,接着反汇编
(gdb) break *0x7c00
Breakpoint 1 at 0x7c00
(gdb) c
Continuing.
Breakpoint 1,0x00007c00 in ?? ()
(gdb) disassemble 0x7c00, 0x9d00
查看寄存器
发现 0x8000 地址开始有数据,提取出来
x/10bx 0x8000
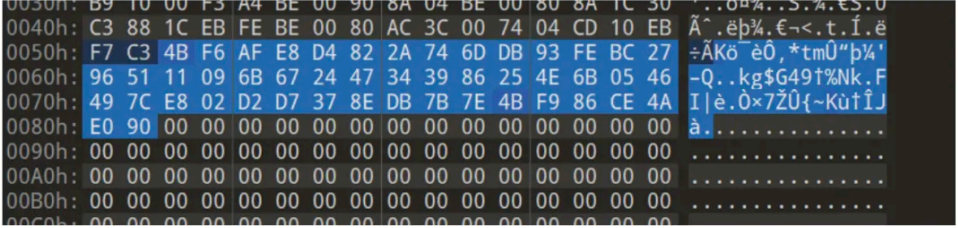
得到
4B F6 AF E8 D4 82 2A 74 6D DB 93 FE BC 27 96 51
11 09 6B 67 24 47 34 39 86 25 4E 6B 05 46 49 7C
E8 02 D2 D7 37 8E DB 7B 7E 4B F9 86 CE 4A E0 90
接着 IDA 打开 main 程序,将⾥边的 key 提取出来
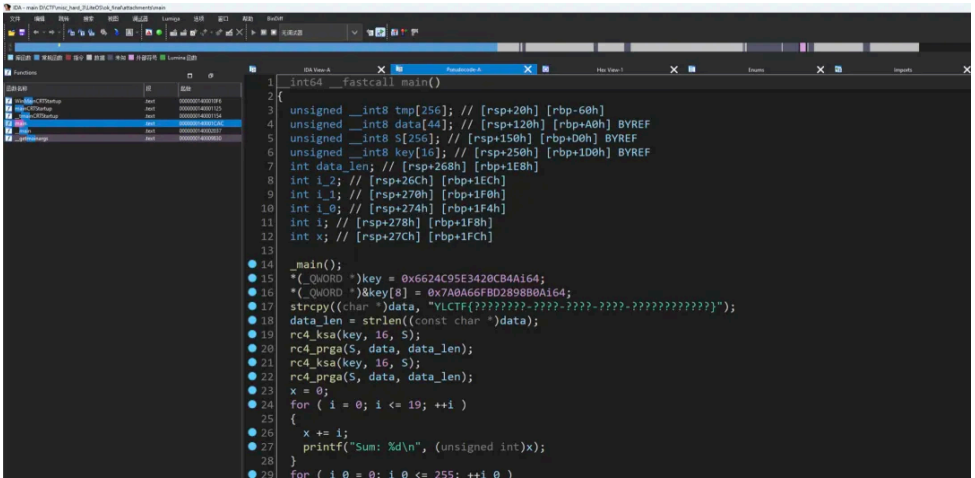
编写脚本解密 AES 即可
from Crypto.Cipher import AES
import binascii
key1 = 0x6624C95E3420CB4A
key2 = 0x7A0A66FBD2898B0A
key = key1.to_bytes(8, byteorder='little') + key2.to_bytes(8, byteorder='little')
flag = '4bf6afe8d4822a746ddb93febc27965111096b672447343986254e6b0546497ce802d2d7378edb7b7e4bf986ce4ae090'
flag = binascii.unhexlify(flag)
cipher = AES.new(key, AES.MODE_ECB)
flag = cipher.decrypt(flag)
print(flag)
# Round 3
# Blackdoor
签到题,解压后⽕绒或 D 盾直接查杀到 include.php 存在⽊⻢,打开找到 password 即为 flag
# Tinted
附件提供了⼀张图⽚,上⾯有很多标有颜⾊的⼩点,根据上⾯的颜⾊,猜测可能是关于⾊彩代码的隐写,根据这个思路利⽤取⾊器。
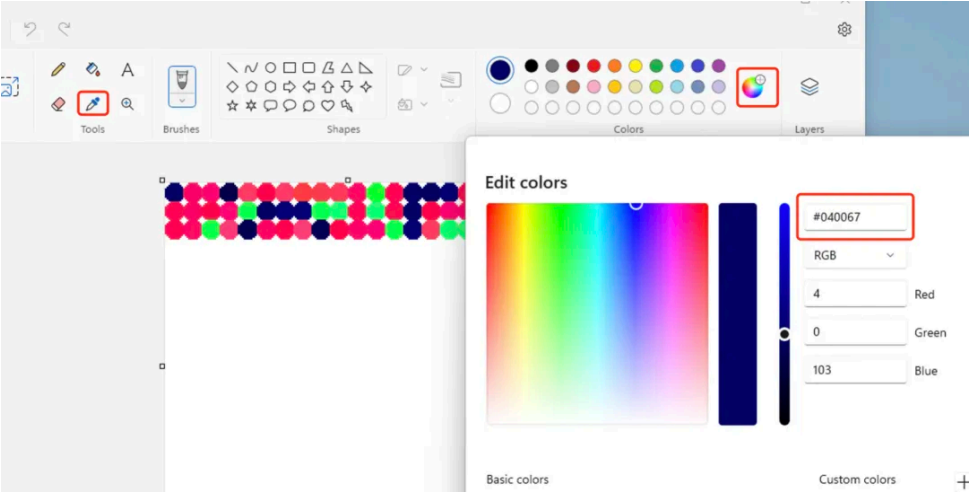
由于上⾯是随机颜⾊,获取完成之后,结果如下:
#040067,#ff0065,#ff0072,#040049,#ff3c66,#ff004a,#ff3c6a,#ff3c42,#ff3c52,
#ff3c5a,#ff0066,#00ff31,#ff0052,#040067,#040062,#040074,#ff0052,#ff004c,
#ff0052,#ff0039,#ff0054,#ff0064,#ff004a,#ff0075,#00ff52,#040063,#040075,
#040075,#00ff53,#00ff74,#ff0057,#00ff75,#ff0051,#040067,#ff004a,#ff0074,
#ff0069,#ff3c5a,#ff0057,#00ff39,#ff0054,#ff0067,#00ff4a,#ff3c7a,#040054,
#ff0064,#ff0052,#ff3c76,#040054,#ff004c,#ff0069,#ff0075,#00ff52,#040074,
#ff3c62,#00ff71,#00ff70,#00ff62,#ff0035,#040035
根据上述的颜⾊代码进⾏分析,发现在最后两位存在问题,可以通过 16 进制转换,编写脚本进⾏提取,代码如下:
import binascii
a = ['#040067', '#ff0065', '#ff0072', '#040049', '#ff3c66', '#ff004a', '#ff3c6a', '#ff3c42', '#ff3c52', '#ff3c5a',
'#ff0066', '#00ff31', '#ff0052', '#040067', '#040062', '#040074', '#ff0052', '#ff004c', '#ff0052', '#ff0039',
'#ff0054', '#ff0064', '#ff004a', '#ff0075', '#00ff52', '#040063', '#040075', '#040075', '#00ff53', '#00ff74',
'#ff0057', '#00ff75', '#ff0051', '#040067', '#ff004a', '#ff0074', '#ff0069', '#ff3c5a', '#ff0057', '#00ff39',
'#ff0054', '#ff0067', '#00ff4a', '#ff3c7a', '#040054', '#ff0064', '#ff0052', '#ff3c76', '#040054', '#ff004c',
'#ff0069', '#ff0075', '#00ff52', '#040074', '#ff3c62', '#00ff71', '#00ff70', '#00ff62', '#ff0035', '#040035']
res = ''
for i in a:
# print(i, i[5:])
res += i[5:]
print(binascii.unhexlify(res))
得到字符串:
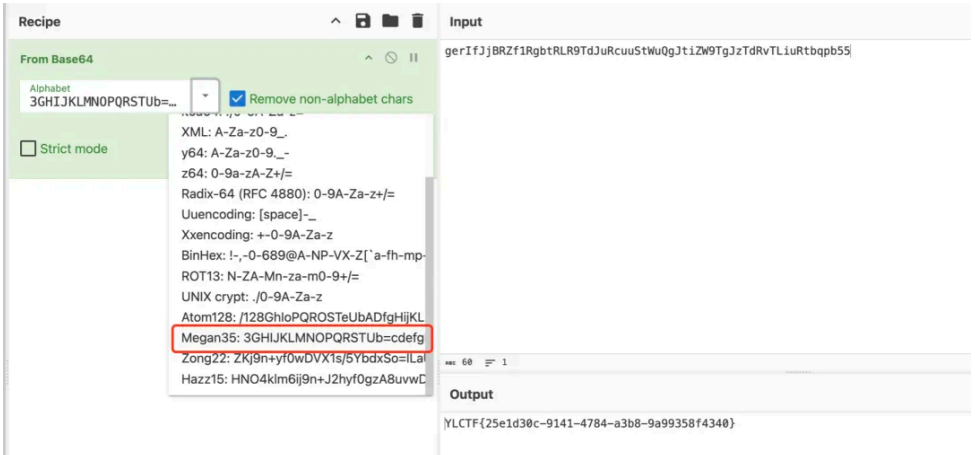
gerIfJjBRZf1RgbtRLR9TdJuRcuuStWuQgJtiZW9TgJzTdRvTLiuRtbqpb55
判断以上为某⼀种编码类型,经过 fuzz 测试可以得到为 base64 换表且为 CyberChef 的默认表。
# figure
提供了⼀个⽂件,打开发现⾥⾯就是⼀⼤堆数据,如下图:

观察最后⾯的数据,发现存在类似于 png ⽂件头的格式,对该数据进⾏反转,并写⼊到⽂件中保存为 png ,发现为⼀张折线图:
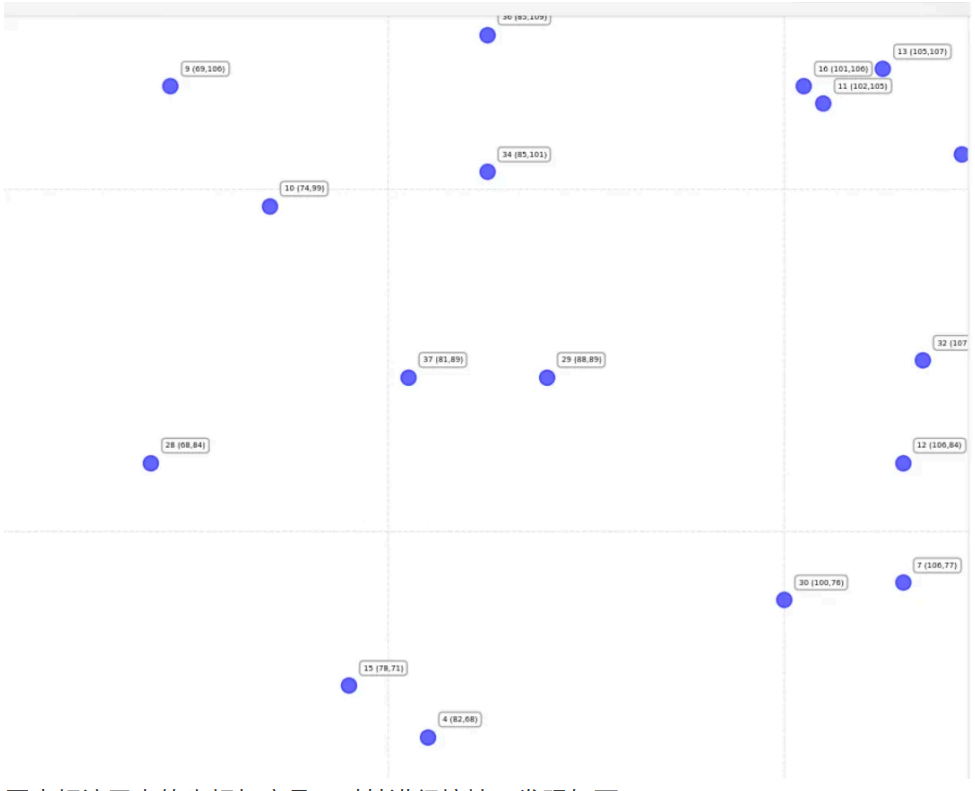
图中标注了点的坐标与序号,对其进⾏摘抄,发现如下:
[(52, 50), (83, 115), (102, 120), (82, 68), (121, 86), (76, 122), (106, 77),
(112, 84), (69, 106), (74, 99), (102, 105), (106, 84), (105, 107), (119, 120),
(78, 71), (101, 106), (71, 120), (66, 112), (119, 57), (87, 49), (49, 82), (115,66),
(55, 71), (113, 65), (114, 89), (116, 77), (111, 103), (68, 84), (88, 89),
(100, 76), (72, 56), (107, 90), (109, 102), (85, 101), (104, 51), (85, 109), (81, 89)]
结合判断这⾥应该要考察的是坐标隐写,x 坐标为前⼀半数据,y 坐标为后⼀半数据整合⼀下,然后在利⽤ ascii 进⾏转换,结果如下:
4SfRyLjpEJfjiwNeGBwW1s7qrtoDXdHkmUhUQYm3efZ8LYTgMYAGBR19pxjGxkTicjTMzVDxs2
对上述的字符串在进⾏分析,发现为栅栏加密(hint2):
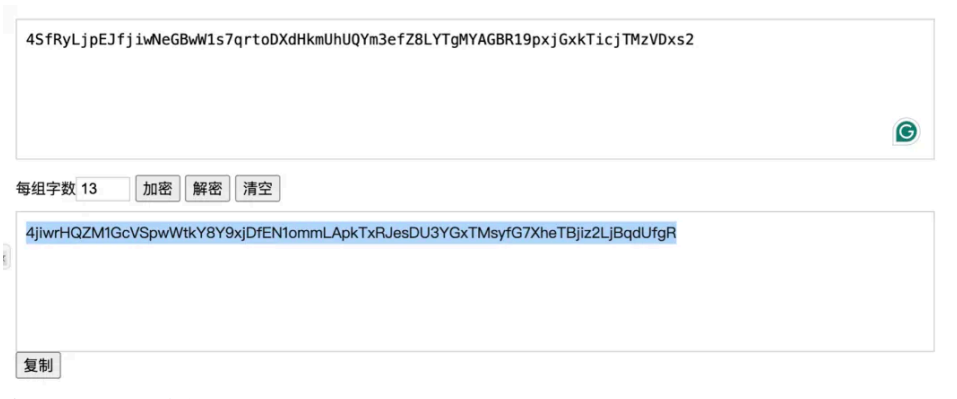
在进⾏以下解密得到 flag:
# CheckImg
开局⼀张图,仔细查看发现 Red plane 0 通道有明显隐写。
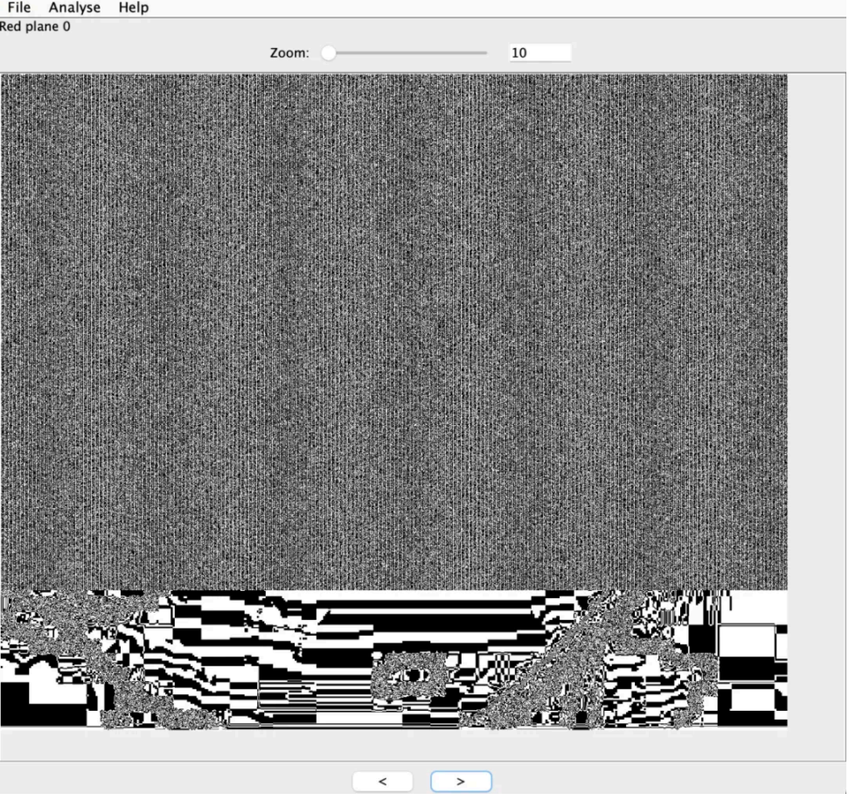
Green plane 0 给了提示,注意细节

先把 Red plane 0 通道的数据给提取出来
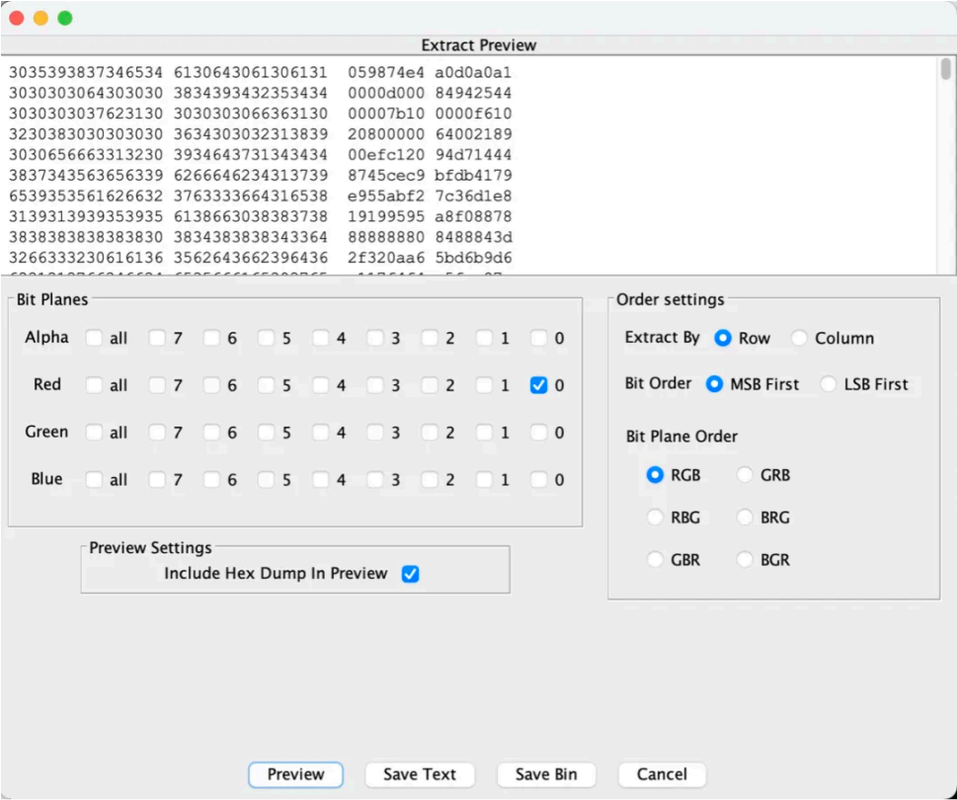
检查隐写的数据,发现是以俩位俩位的转
写个脚本反转⼀下:
def reverse_string(s):
s = list(s)
for i in range(0, len(s), 4):
s[i:i+4] = s[i:i+4][::-1]
return ''.join(s)
f = open('data.txt', 'rb')
data = f.read().decode('utf-8')
print(reverse_string(data))
导入到 010 恢复成 png,得到另⼀张图⽚
很明显可以看出图⽚对 IDAT 块进⾏了隐写,使⽤ zsteg 查看图⽚隐写的数据,得到 DNA 编码
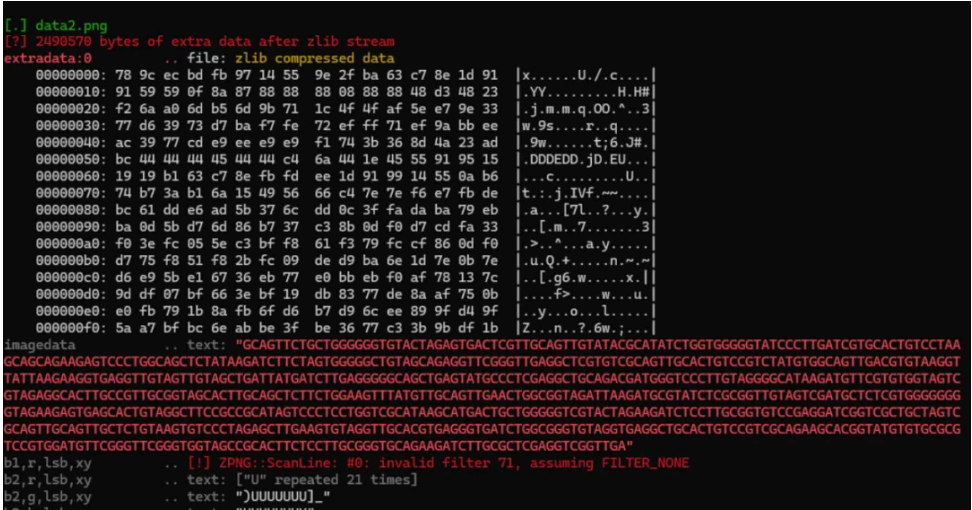
import sys
bin_dna = {'00':'A','10':'C','01':'G','11':'T'}
mapping = {
'AAA':'a','AAC':'b','AAG':'c','AAT':'d','ACA':'e','ACC':'f', 'ACG':'g',
'ACT':'h','AGA':'i','AGC':'j','AGG':'k','AGT':'l','ATA':'m','ATC':'n','ATG':'o',
'ATT':'p','CAA':'q','CAC':'r','CAG':'s','CAT':'t','CCA':'u','CCC':'v','CCG':'w',
'CCT':'x','CGA':'y','CGC':'z','CGG':'A','CGT':'B','CTA':'C','CTC':'D','CTG':'E',
'CTT':'F','GAA':'G','GAC':'H','GAG':'I','GAT':'J','GCA':'K','GCC':'L','GCG':'M',
'GCT':'N','GGA':'O','GGC':'P','GGG':'Q','GGT':'R','GTA':'S','GTC':'T','GTG':'U',
'GTT':'V','TAA':'W','TAC':'X','TAG':'Y','TAT':'Z','TCA':'1','TCC':'2','TCG':'3',
'TCT':'4','TGA':'5','TGC':'6','TGG':'7','TGT':'8','TTA':'9','TTC':'0','TTG':' ',
'TTT':'.'}
def bin_2_code(string):
string = string.replace(" ","")
string = string.replace("\n","")
final=""
for j in range(0,len(string),2):
final+=bin_dna[string[j:j+2]]
return final
def decode_dna(string):
final=""
for i in range(0,len(string),3):
final+=mapping[string[i:i+3]]
return final
print(decode_dna("GCAGTTCTGCTGGGGGGTGTACTAGAGTGACTCGTTGCAGTTGTATACGCATATCTGGTGG
GGGTATCCCTTGATCGTGCACTGTCCTAAGCAGCAGAAGAGTCCCTGGCAGCTCTATAAGATCTTCTAGTGGGGGCTGT
AGCAGAGGTTCGGGTTGAGGCTCGTGTCGCAGTTGCACTGTCCGTCTATGTGGCAGTTGACGTGTAAGGTTATTAAGAA
GGTGAGGTTGTAGTTGTAGCTGATTATGATCTTGAGGGGGCAGCTGAGTATGCCCTCGAGGCTGCAGACGATGGGTCCC
TTGTAGGGGCATAAGATGTTCGTGTGGTAGTCGTAGAGGCACTTGCCGTTGCGGTAGCACTTGCAGCTCTTCTGGAAGT
TTATGTTGCAGTTGAACTGGCGGTAGATTAAGATGCGTATCTCGCGGTTGTAGTCGATGCTCTCGTGGGGGGGGTAGAA
GAGTGAGCACTGTAGGCTTCCGCCGCATAGTCCCTCCTGGTCGCATAAGCATGACTGCTGGGGGTCGTACTAGAAGATC
TCCTTGCGGTGTCCGAGGATCGGTCGCTGCTAGTCGCAGTTGCAGTTGCTCTGTAAGTGTCCCTAGAGCTTGAAGTGTA
GGTTGCACGTGAGGGTGATCTGGCGGGTGTAGGTGAGGCTGCACTGTCCGTCGCAGAAGCACGGTATGTGTGCGCGTCC
GTGGATGTTCGGGTTCGGGTGGTAGCCGCACTTCTCCTTGCGGGTGCAGAAGATCTTGCGCTCGAGGTCGGTTGA"))
将数据进⾏ DNA 解码,得到
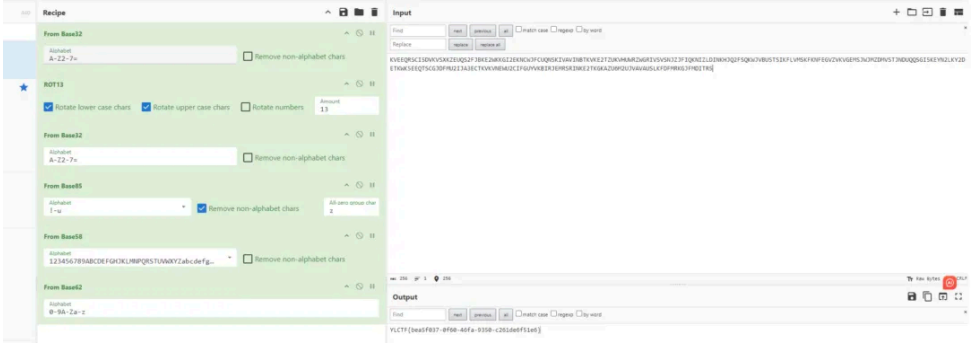
KVEEQRSCI5DVKVSXKZEUQS2FJBKE2WKKGI2EKNCWJFCUQNSKIVAVINBTKVKE2TZUKVHUWRZWGRIVSVS NJZJFIQKNIZLDINKHJQ2FSQKWJVBUSTSIKFLVMSKFKNFEGVZVKVGEMSJWJMZDMVSTJNDUQQSGI5KEYN 2LKY2DETKWK5EEQTSCGJDFMU2IJA3ECTKVKVNEWU2CIFGUYVKBIRJEMRSRINKE2TKGKAZU6M2UJVAVA USLKFDFMRKGJFMDITR5
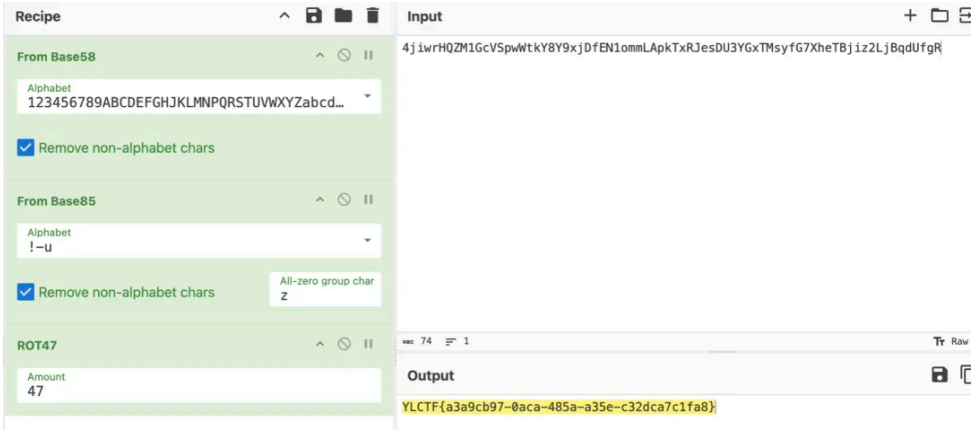
接下来就是编码套娃,按下⾯顺序解即可 (base32-rot13-base32-base85-base58-base62)